
設計檢索系統時,需要透過評估指標 (Evaluation Metric) 來判斷檢索系統的結果好壞,在此列出檢索的幾種指標。
混淆矩陣
首先先來認識基礎的混淆矩陣。
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Positive |
True Positive (TP) | False Negative (FN) |
| Negative |
False Positive (FP) | True Negative (TN) |
準確度 (Accuracy)
準確度表示:預測正確資料佔所有資料的比例。
- 公式:
(TP + TN) / (TP + TN + FP + FN) - 資料正反比例不平衡時,準確率參考價值會變低
- 例如罕見疾病的預測,100 人中只有 1 位病人,全部預測為健康的準確率也有 99 %。
精確度 (Precision)
精確度表示:預測正確陽性佔預測陽性的比例,越高越好。
- 公式:
TP / (TP + FP)
這個指標比較適用於檢索,其代表意義為:檢索的相關項目數 / 所有檢索項目,不列入大量的 TN (未檢索也不相關的項目) 和 FN (未檢索但相關的項目),強調整體預測結果的正確程度。
召回率 (Recall)
預測正確陽性佔實際陽性的比例,越高越好。
- 公式:
TP / (TP + FN)
在檢索的代表意義為:檢索的相關項目數 / 所有相關項目,表示是否把所有的關聯資料都列出來。
接下來我們可以延伸出幾個指標:
Precision@K 和 Recall@K
假設檢索系統輸入關鍵字以後,可以顯示前 k 個關鍵字,可以用以下的指標來判斷:
- Precision@K:前 k 項中檢索的相關項目數 / K,用來評估排名前 K 個結果的準確性。
- Recall@K:前 k 項中檢索的相關項目數 / 所有相關項目 (如果 K 選擇得太小,可能無法全面評估系統的召回能力)。
平均精確度 AP@K
是 Average Precision 的縮寫,計算所有可能的 K 值的加權平均。
- 公式:
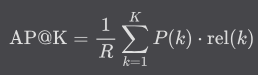
- K 是考慮的前 K 個結果的數量。
- R 是相關結果的總數。
- P(k) 是前 k 個結果中的精確率。
- rel(k) 是第 k 個結果是否相關的指標,相關為 1,不相關為 0。
如果關聯項目越前面的話,則數值越高。
DCG 和 nDCG
DCG 是相關度分數的加總。如果文件有關聯度的高低,則此指標可用於檢視不同關聯度文件的排序優劣,關聯越高應該排越前面。
- 公式:
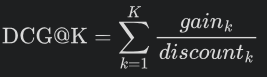
nDCG 將 DCG 轉為 0 ~ 1 之間的浮點數,會參考到 IDCG (即最優排序下的 DCG)。
F1-Score
F1-score 是 Precision 和 Recall 的調和平均數。
- 公式:
