
在 GTC 2018 接觸到的智慧型機器人與強化學習 (Reinforcement Learning) 的心得整理。
介紹
這是當天議程的演講之一,也有發表在 NVIDIA Jetson Developer Challenge 的網站上,裡面包含相關的論文。

裡面有幾個特色:
- 以往相關實驗是使用光達 (Lidar) 作為感測器,這邊使用較為便宜的 RGBD 相機替代。
- 在虛擬世界訓練出來的模型,套用在現實環境的辨識上,由於兩個環境差異很大,不一定會有很好的效果。因此這篇論文使用 Semantic Image Segmentation,將現實和虛擬環境都用色塊著色、標示重要資訊,以減少環境差異,加強訓練效果。
- Asynchronous Advantage Actor-Critic 演算法:是一種強化學習的方式。使用 Actor-Critic 演算法,讓 Critic 不斷評估 Actor 的動作分數,讓 Actor 不斷調整自己,取得更高分。而 Asynchronous Advantage Actor-Critic 則是平行訓練多個 Actor-Critic,並將結果更新至 Global Parameters 上。
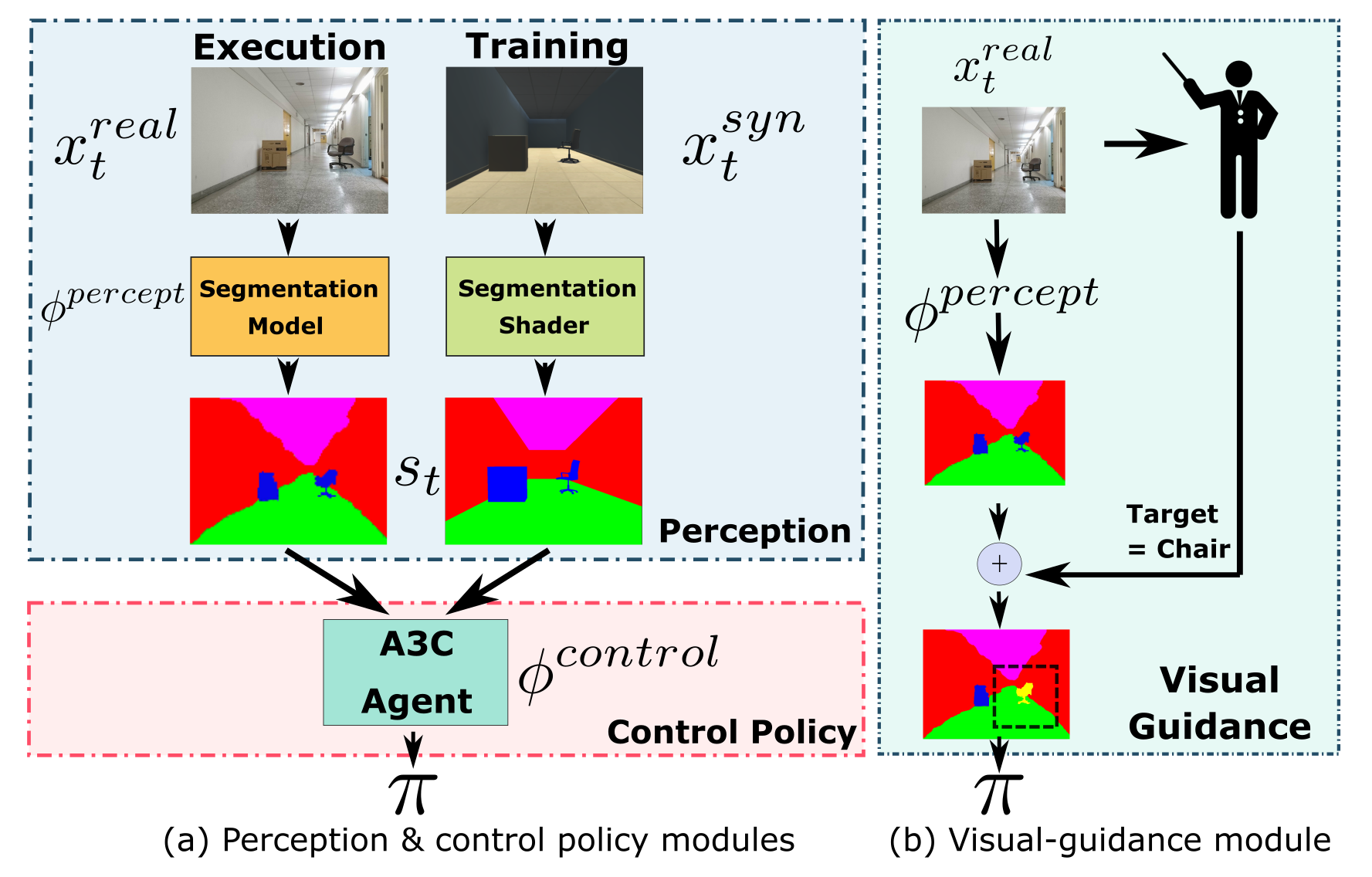
- 註: 這個演講與論文發表於 2018 年,對於機器人的自主行動,現在可能有更好的方式。
- 註 2: 圖片擷取自上方的競賽網站。