
建立 SQL Server 索引時要注意的地方,可能會對查詢效能產生不小的影響。
說明
SQL Server 在建立索引時,內部結構其實是樹狀結構。
而我們在建立索引的時候,資料行 (欄位) 的順序,會決定其在樹狀結果的節點在第幾層,而影響查詢時使用索引的效率。
以下是微軟的說明:
如果索引包含多個資料行,可考慮資料行的順序。 用於 WHERE 子句等於 (
=)、大於 (>)、小於 (<) 或BETWEEN搜尋條件中的資料行,或是參與聯結的資料行,應該放在第一位。 其他資料行應該按照它們的區分程度排序,亦即,從最能區分的排到最不能區分的。例如,如果索引定義為
LastName、FirstName,當搜尋條件是WHERE LastName = 'Smith'或WHERE LastName = Smith AND FirstName LIKE 'J%'時索引就會很有用。 但是,查詢最佳化工具不會為只搜尋FirstName(WHERE FirstName = 'Jane') 的查詢使用索引。
以上述的例子來說,索引欄位順序為:
CREATE NONCLUSTERED INDEX NameIndex on Table1
(
LastName,
FirstName
)
則只有查詢條件包含 LastName 時會使用索引:
| LastName | FirstName |
|---|---|
| Smith | Will |
| Smith | Jimmy |
| Birkin | Jane |
| Sam | Lonely |
SELECT LastName, FirstName FROM Table1
WHERE LastName = 'Smith' -- 會搜尋索引
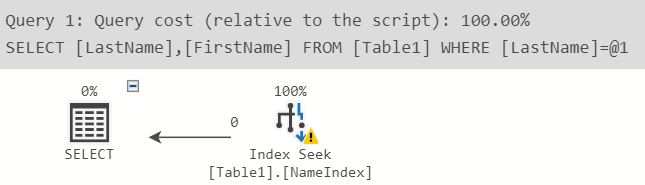
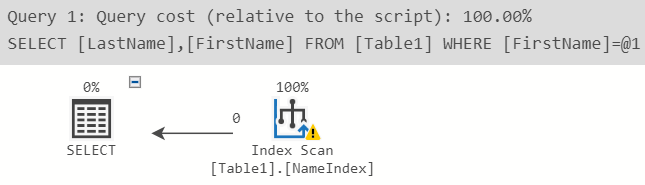
SELECT LastName, FirstName FROM Table1
WHERE FirstName = 'Jane' -- 會掃描整個索引 (較慢)
另外要注意的是,越能夠分出資料差異的欄位,要放在索引更前面的位置。這也和我們常使用的查詢條件有關,因此可能會需要針對不同查詢建立不同順序的索引。
以下面資料為例,使用 Sex 欄位做索引的話,因為裡面通常只有 M 和 F 兩個值,差異程度低的話會需要造訪較多節點,索引效率會比 Year 欄位來得差。
| Year | Sex | Name |
|---|---|---|
| 1992 | M | Will |
| 1993 | M | Jimmy |
| 1995 | F | Jane |
| 1993 | M | Sam |
| 1994 | F | Annie |
參考資料
- 微軟的說明:SQL Server 及 Azure SQL 索引架構與設計指南 - SQL Server - Microsoft Learn
- 更加理解 SQL Index 的設計:The Leaf Nodes of an SQL Index
- 從回答理解 SQL Server 的索引設計:sql - How important is the order of columns in indexes? - Stack Overflow