
因為 SQL Server 用 TOP 或 ORDER BY 查詢,都只能取得特定順序的資料,想要從資料表內取得隨機資料 (通常是用來測試或檢查資料正確性,或是拿來產生抽獎名單),可以使用 NEWID() 語法。
NEWID() 用法
以下是最簡單的用法:
SELECT TOP (1000) * FROM TableName ORDER BY NEWID()
NEWID() 會產生隨機 uniqueidentifier 類型資料,因此可以依亂數取得資料。
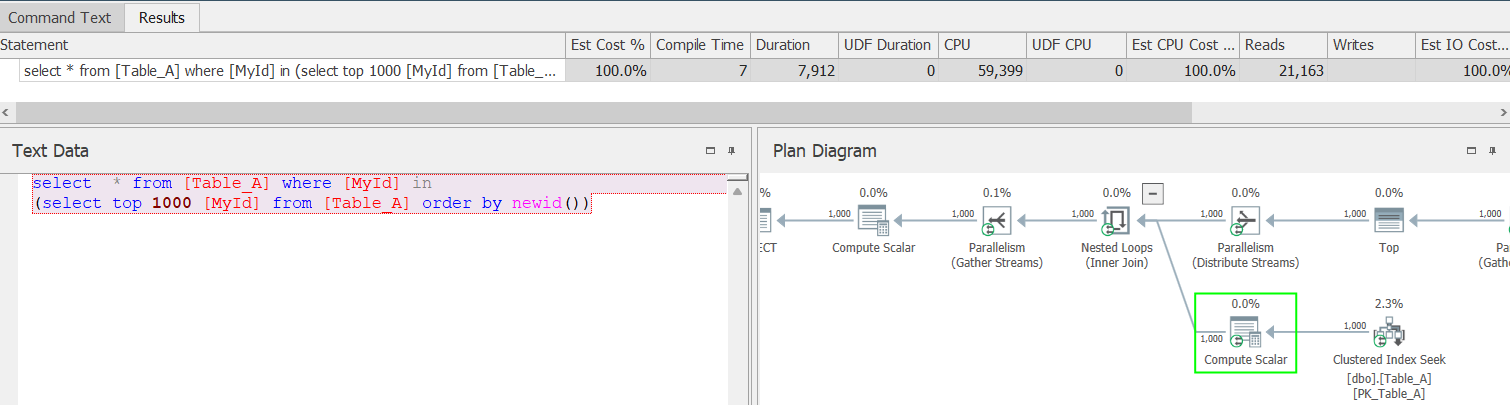
不過因為要處理整個資料表,速度會比較慢,因此如果要在較多資料的資料表查詢,可以使用以下語法,只針對資料表的 Primary Key 產生亂數,減少對其它欄位的計算,以加快取回資料的速度。
SELECT * FROM TableName WHERE [PrimaryKey] IN
(SELECT TOP (1000) [PrimaryKey] FROM [TableName] ORDER BY NEWID())
關於效能
直接使用 NEWID() 時,因為要處理整個資料表,從實際執行計畫可以看到讀取量 (Reads) 和時間 (Duration) 都較高。

如果先針對 Primary Key 產生亂數,再取得資料的話,從執行計畫可看出讀取量較少,也有用到索引取得其它欄位資料,花費時間較低。
Bonus: 什麼是 uniqueidentifier 資料型別
uniqueidentifier 是 SQL Server 的一種資料型別,用來儲存 GUID(Globally Unique Identifier,全域唯一識別碼)。它是一個 128 位元(16 byte)的值,格式像這樣:
A3F0F13E-0C21-4F47-A9A5-52B947DFA330
透過 SQL Server 的 NEWID() 函數可以產生一個新的 uniqueidentifier 值,因此當我們使用 ORDER BY NEWID() 時,系統會為每一列資料產生一個隨機的 uniqueidentifier,再根據這些隨機值排序,達到隨機取樣的效果。